Обновлено 4 апреля 2026
CursorBench: как Cursor оценивает качество моделей
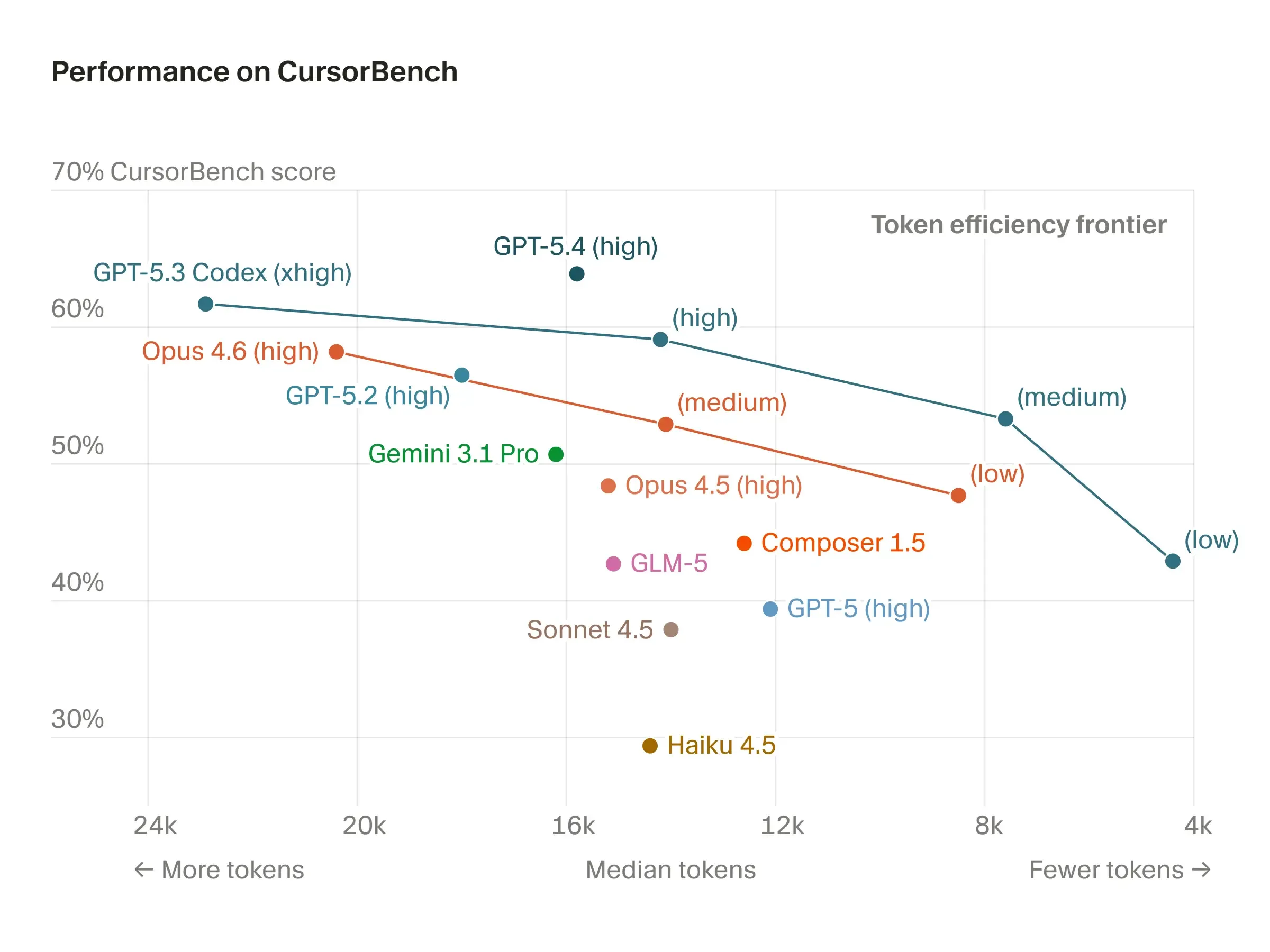
Публичные бенчмарки вроде HumanEval или SWE-bench плохо отражают реальную работу с AI-ассистентом: задачи там короткие, контекст искусственный, а разработчики всё чаще просят агента решать многошаговые задачи с несколькими файлами и инструментами.
В Cursor используют гибридный подход: офлайн-сюит CursorBench плюс онлайн-анализ живого трафика. CursorBench строится на реальных сессиях инженеров Cursor — не на публичных репозиториях. Задачи взяты из настоящего использования продукта, поэтому сюит лучше разделяет модели между собой и точнее предсказывает, как разработчик оценит результат.
Оценивают несколько измерений: корректность решения, качество кода, эффективность и поведение в диалоге. Офлайн-тесты дополняют контролируемым анализом на проде — онлайн-эвалы ловят регрессии, которые не видны в офлайне: когда вывод формально правильный, но на практике ощущается хуже.
Такой цикл держит представление о качестве моделей привязанным к реальным сценариям и помогает выстраивать лучший агентский опыт в Cursor.
Источник: How we compare model quality in Cursor